The NFL draft is as popular of a sports topic as anything that actually involves sports. Spread out over three days it might seem like an endurance event, but really it seems more like a sprint placed cleverly in the middle of offseason with football fans of both the collegiate and the professional variety hungry for action of some kind.
I recently saw an interesting graphic shown below (click for full size).
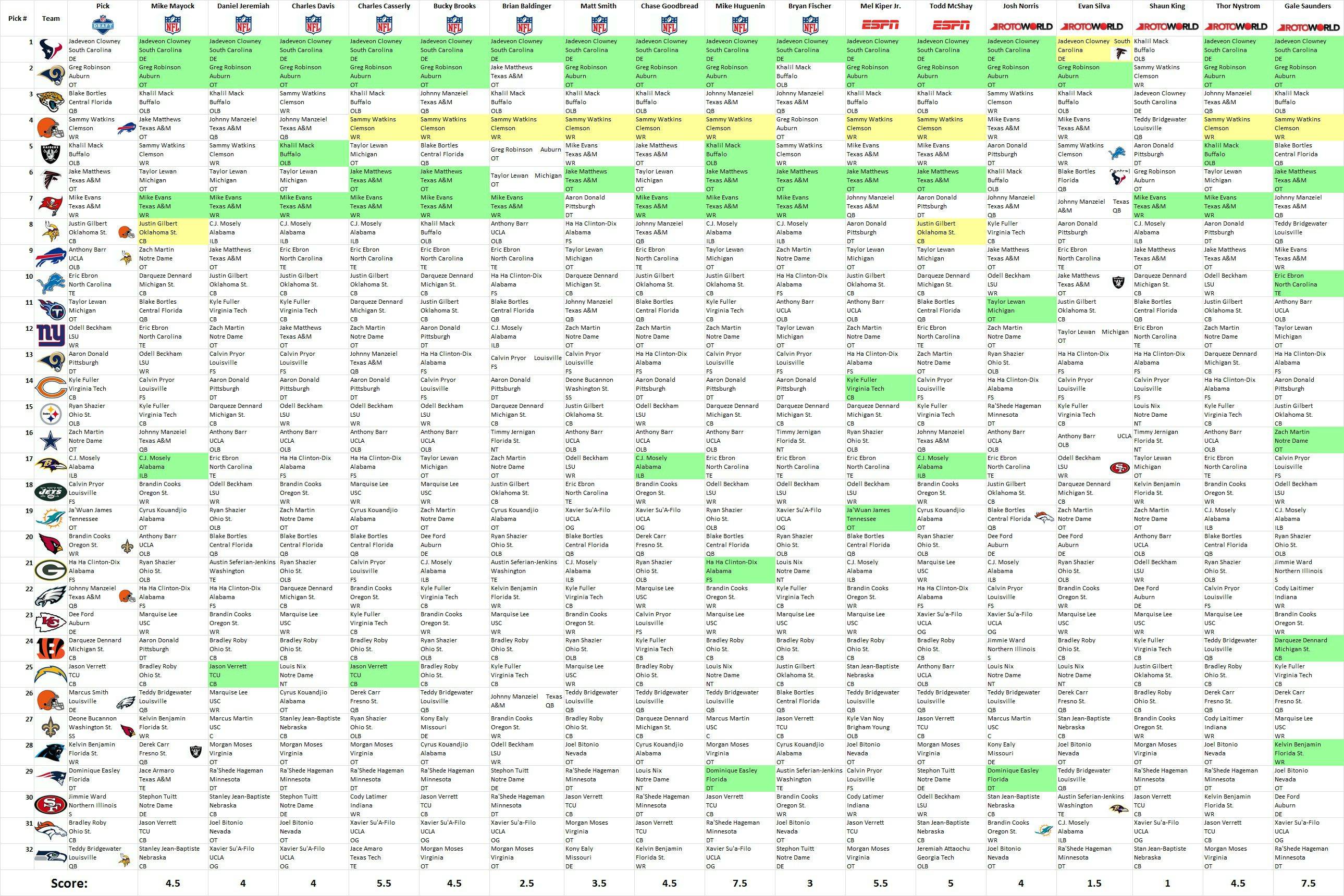
The green boxes highlight totally correct picks and the yellow boxes highlight the correct player but the wrong team (when teams traded picks). The scores at the bottom are the number of totally correct picks plus half the number of partially correct picks. No analyst listed has more than one partially correct pick.
I wanted to know how much better than “random” this representative sample was.
I’m going to throw some numbers around, correct me if you think they should be corrected. Recalculating things isn’t too hard.
Suppose that we can come up with 50 players who might go in the first round (the top 50 players on the board), but completely unordered (that is, there is no reason to believe that, say, Clowney, will get picked near the top). Suppose I randomly order 32 of those players. How many would I get correct? We’ll ignore pick trading (making every “yellow” a “green” and rounding up all the .5’s).
I feel too lazy to do the math, so I’ll roll the dice a few (million) times instead. I created two shuffled lists of numbers from 1-50 and compared how many of the first 32 numbers of each were the same. I then repeated this 1,000,000 times just to be sure. Think of this as monkeys at a typewriter spitting out drafts (of either the NFL variety or the Shakespearean).
Results: I would expect to get about 0.64 picks correct with this (random out of top 50 players) random strategy. 34% of the time I got exactly one pick correct while 47% of the time I get at least one pick correct.
Certainly everyone on this list did better than this, as one would hope. That said, those near the bottom (those scoring one and two – Shaun King and Evan Silva respectively) didn’t do that well. 14% of the time I got more than one pick correct and 3% of the time I got more than two picks correct.
Of the one million monkeys (or the one million drafts of the draft from one monkey) the maximum score I got was an eight (a score that two of the reporters shared) one time, making their predictions about one in a million out of my technique. That is, I feel fairly confident that their techniques are better than randomly shuffling the top 50 players into place. Those at the bottom, I am not so sure.

I can think of two things. The first is that the players drafted first are typically going to go to the worst team in the league. It is hard to shine when everyone else around you is terrible. Moreover you probably need to play day one with no star ahead of you to groom you for a year or two (I have no idea if that concept actually works or not).
The other thing is that teams with the first pick (again, presumably the worst team in the league) hasn’t gotten there by accident. They probably have scouted poorly for the last few years to get to the bottom, and they will probably continue to scout and pick poorly now.
Also, great video with the double Shakespeare tie in.
Yes, context is important, but if there’s insurmountable unpredictability– one variety of which you’ve documented above– at work, his well-illustrated point is that the difference between the first and second picks is negligible. Because the first pick is considered more valuable than the second, why not extract some of that surplus value and trade down for the second pick if you can?
No doubt. My instinct, especially if I had a top four overall pick, would be to trade down to a pile of second round picks. Of course, if top picks start to get too devalued then this doesn’t work anymore.
Related?
http://deadspin.com/espns-chad-ford-has-been-retroactively-editing-draft-bo-1681631642
I just read several pages of comments about Michigan’s newest theft today. I kept thinking about this sort of topic though – that a player’s performance at the next level is much less sure than we think it is. Part of that is due to over analysis. There are a lot of journalists writing about everything and the draft for any sport typically comes squarely in the off season, with writers struggling to come up with content. But anyone who does data analysis knows about the perils of overfitting. Claiming to know exactly where a player will get drafted will lead to wildly inaccurate results (as I have shown in my original post here). Similarly, for HS athletes going to college it is very hard to determine who will be a starter and who will sit for four years. I would be surprised if more retroactive editing of predictions for players moving to the next league doesn’t happen every year.
And to people making predictions: Own your predictions, analyze them, and be honest. If you weren’t successful look at your strategy and see where it fails. Modify and try again. Eventually you may have a winning prediction algorithm. In any case, you will learn a lot about what you value in an athlete and what others value.